| 记一次kafka消费延迟造成的生产问题 | 您所在的位置:网站首页 › kafka lag产生的原因 › 记一次kafka消费延迟造成的生产问题 |
记一次kafka消费延迟造成的生产问题
|
背景介绍
今天有同事找我,说他那边遇到kafka消费延迟问题,某条消息从生产者发送后,再到消费者收到,经过了几分钟的时间,之后又恢复正常,时不时会遇到一次这样的问题。 简单分析当我一听到消费延迟的问题,很自然的就想到了肯定消息阻塞造成的,所以首先我们查看了消息队列的消费情况,发现当前并没有消息积压在kafka服务端,之后我们也确认了kafka集群很正常,没有出现任何异常现象。 进一步分析虽然表面上看消息并没有积压,但凭借经验,我感觉还是这方面的问题,既然kafka服务端自身没有积压,那一定就是消费端自己出了问题,我又让同事去查在收到那条延迟消息之前,最近一次的消费情况,果然发现上一次的消费发生了问题,在某个条件下会导致业务处理产生超长的时间,并且由于是串行处理的方式,影响了后续的消费,导致消息延迟,实际上kafka服务端肯定是产生了消息积压,只是由于业务量不大,没触发到积压的告警阈值,且当我们检查积压情况时,已经恢复到了正常的消费情况,造成了一种消息没有积压的假象。 造成问题的原因在处理问题的整个过程中,我发现有很多可优化的点,下面我将一条条来说明。 1、分区与消费者对应问题同事想通过增加分区数来提供消费者的消费能力 我发现还是有很多同学,不理解这一块的对应关系,认为当消费者消费能力不足时,只需要增加分区数量就可以解决,我遇到很多是这样理解的同学,实际上,kafka中分区只能被一个消费者消费,如果你的消费者只有2个,那么分区数建立超过2个以上是没有意义的(因为此时你并不是生产能力的不足,而是消费能力的不足,增加再多分区数,消费者数量不变,消费能力是不会提升的),消费者的数量决定了你的上限,当然,反过来,如果你的消费者有4个,那你只建立了两个2分区,那就浪费了另外2个消费者的资源,此时如果选择再增加2个分区就有意义了。关于分区和消费的详细介绍,可以参考我的另一篇博文:Kafka中关于分区的一些理解。 2、消息中的key为什么我们的消息使用发往同一个分区? 我们的kafka是直接在阿里云上购买的,好像是因为阿里云有对topic使用数量的限制,所以我们一般业务上会在消息中使用key来进行不同业务处理的分类,这样就避免了一种业务对应一个topic的情况,但是同时又会带来另一个问题,kafka默认情况下,如果你发送消息时带了key,那么它就会根据key值先进行hash计算,得到一个int值后,再与分区数取模,最后这个取模后的结果就是消息要发往的分区。 所以这就解释了,为什么我们生产上虽然有4台服务,但消息始终都发往同一个分区,也就是始终只有一个消费者在消费。 那么实际上,我们是可以通过重写分区策略的方式,来实现带key值发送时,也可以均匀的把消息发到每个分区上的,这个很简单,可自行百度。 3、同步消费未考虑使用线程池的方式 尽管未使用多线程不是造成这个问题的直接原因,但如果这里的业务采用线程池的方式,也不会发生这个原因,因为那个耗时很长的业务场景并不多,大多数情况下,消费端还是能够很快处理的,所以每次也就最多会有1个线程被那个耗时很长的业务hang住,对于其他的业务场景并不影响。 当然使用线程池主要还是为了能够使消费者的资源得到充分的利用,根据上面的说明,一个分区只能被一个消费者消费,那么通常情况下对于消费者来说,如果只处理一个分区的消息,显得有点太浪费了,所以我们可以选择让一个消费者分配多个分区,然后采用异步消费的方式,开启多线程提高并行处理的能力。 4、关于concurrency参数使用concurrency参数有没有用? 这是spring在为我们整合kafka时,提供的参数配置,同事问我,把这个配置高一点是否有用,我的回答是,因为我们有前面介绍过有key的问题,导致消息只会发往一个分区中,所以配置concurrency参数是没有用,这个参数的作用其实就是spring帮我们在一个应用实例中创建了多个消费者,以此来实现并行消费的能力,注意创建的是消费者,记住,一个分区只能被一个消费者消费。 所以,这个参数应用的场景是,当你应用实例要小于分区数时,且一个应用实例如果只消费一个分区,又不能充分利用其资源时,则可以考虑使用这个参数,它可以方便的为我们构造出多个消费者,不需要你自己去开启多线程(concurrency实现原理还是开启的多线程的方式),从而实现并行消费,不过你任然要牢记,如果你的应用实例 乘以 concurrency的数值,超过了分区数时,则会造成资源浪费。 Spring整合Kafka消费端concurrency参数设置,这篇文章中我也详细分析了concurrency参数的具体实现。 总结经过这次问题分析后可以发现,大家对于kafka的理解还是有点不足,首先,应用上没有正确的使用,分区与消费者的关系也没有缕清,其次,各种参数的作用与调配也一知半解。 优秀的中间件可以极大的减少我们开发的成本,让我们不必自己造轮子,但作为一名开发人员,你真的不能像听产品介绍一样,拿来即用,有些原理上的东西还是要稍作了解的,不然一旦出现了问题你可能根本无法解决, 希望通过本次简单的分析,对这方面存在同样问题的同学有所帮助。 |
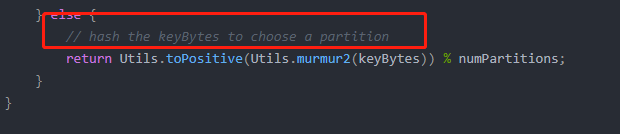 kafka生产者消息发送的流程与参数配置,这篇文章中有详细介绍生产者的发送流程,其中第四步描述了kafka是如何决定消息应该发往哪个分区的。
kafka生产者消息发送的流程与参数配置,这篇文章中有详细介绍生产者的发送流程,其中第四步描述了kafka是如何决定消息应该发往哪个分区的。【本文地址】